SQL Basics
SQL (Structured Query Language)
- Always case-insensitive (even table and attributes names)
- Semicolon
;to indicate command termination are mandatory in MySQL terminal - Use
--for single-line comment /* */(multi-line commnents)- Declarative language
Glossary
- Relation (Table)
- Attribute & Field (Column), Degree (no. of attributes)
- Tuple & Record (Row), Cardinality (no. of tuples)
- Projection (subset of columns displayed as the final output)
Types of Commands
- DDL (create, alter, truncate) (modifies schema)
- DML (insert, delete, update) (modifies table data)
- DCL (grant, revoke)
- DQL (select)
- TCL (begin, commit, savepoint, rollback)
Storage Engines
https://www.mysqltutorial.org/understand-mysql-table-types-innodb-myisam.aspx
The internal engine that runs stuff and we can leverage many features of different engines available. We can also specify a different engine to use for different tables.
A total of 9 storage engines are available in MySQL. Postgres has only 1.
Default is: InnoDB
Logging into the MySQL Server
$ mysql -u username -p
Enter Password: ********
Databases
CREATE DATABASE [IF NOT EXISTS] db_name;
DROP DATABASE [IF EXISTS] db_name;
SHOW DATABASES;
USE db_name;
Importing an external DB
SOURCE c:\path\to\db_name.sql
Data Types
https://www.tutorialspoint.com/mysql/mysql-data-types.htm
CREATE TABLE
CREATE TABLE [IF NOT EXISTS] table_name(
column_1_definition,
column_2_definition,
...,
table_constraints
) ENGINE=storage_engine;
CREATE TABLE employee(
emp_id INT PRIMARY KEY,
emp_name VARCHAR(50),
doj DATE,
);
CREATE TABLE t_name(
serial_no INT NOT NULL AUTO_INCREMENT, -- PRIMARY KEY (alternatively)
emp_id INT NOT NULL,
emp_name VARCHAR(25) NOT NULL,
doj DATE,
PRIMARY KEY (emp_id) --single column only, multiple => CONSTRAINT combined_pk_alias PRIMARY KEY (ID,LastName)
);
CREATE TABLE AS
CREATE TABLE TestTable AS
SELECT customername, contactname
FROM customers;
(*Creating one table from another by projection, this copies row data too)
CREATE TABLE emp1 AS
SELECT * FROM emp
WHERE 1=2; --false condition; no data from where clause
(*Copying only the schema)
DROP TABLE
DROP TABLE [IF EXISTS] t_name, t2_name; or simply DROP TABLE t_name;
(delete data as well as schema)
TRUNCATE
TRUNCATE TABLE t_name;
(delete all data but keep schema)
DESCRIBE
DESCRIBE table_name;
(display the schema of the table)
ALTER TABLE
ALTER TABLE t_name
ADD c_name varchar(10)
[ FIRST | AFTER column_name],
ADD c2_name varchar(100)
[ FIRST | AFTER column_name];
ALTER TABLE t_name
MODIFY c_name varchar(20),
MODIFY c2_name varchar(90);
ALTER TABLE t_name
CHANGE COLUMN old_name new_name
[ FIRST | AFTER column_name];
ALTER TABLE t_name
DROP COLUMN c_name;
ALTER TABLE t_name
RENAME TO new_t_name;
In Postgres, MODIFY isn’t avaialble but RENAME COLUMN, ADD COLUMN, ALTER COLUMN are. Differs slightly based on different providers.
RENAME TABLE
RENAME TABLE old_table_name TO new_table_name;
(*for renaming temporary tables use ALTER TABLE RENAME TO)
INSERT INTO
INSERT INTO t_name(attrib1, attrib2, ... attribN)
VALUES
(v11,v12,...),
(v21,v22,...),
...
(vnn,vn2,...);
-- No need to specify attribute list if filling all attributes:
INSERT INTO t_name VALUES (value1, value2, ... valueN);
SELECT
SELECT [DISTINCT] Attribute_List FROM T1,T2…TM
[WHERE condition1 [AND/OR... condition2]]
[GROUP BY (Attributes)[HAVING condition]]
[ORDER BY(Attributes)[ASC/DESC]];
(Uses ASC by default)
Operators in WHERE
-
Relational (=, !=, <, >, <=, >=)
-
condition1 AND/OR/NOT condition2 … and so on..
-
LIKE/NOT LIKE
SELECT * FROM Customers WHERE City LIKE 's%';(%= *,_= .) Case-insensitiveILIKEalso available in Postgres. Escape sequences can also be usedLIKE '__\%', matches99% -
BETWEEN, NOT BETWEEN
SELECT * FROM Products WHERE Price BETWEEN 50 AND 60; -
IN/NOT IN
SELECT * FROM Customers WHERE City IN ('Paris','London');(Ex -IN (subquery)) -
IS NULL/IS NOT NULL
SELECT column_names FROM table_name WHERE column_name IS NULL;
REGEXP
SELECT first_name FROM person_tbl WHERE first_name REGEXP '^a.*';
LIMIT / OFFSET
It limits the result-set (WHERE clause’s output) which may or may not be the final output (projection).
SELECT field1, field2,...fieldN
FROM table_name1, table_name2...
[WHERE Clause]
[LIMIT N] [OFFSET M ]
SELECT field1, field2,...fieldN
FROM table_name1, table_name2...
[WHERE Clause]
LIMIT [offset_value,] limit_value
select long_w from station
where lat_n > 38 order by lat_n asc limit 1;
-- selects long_w for a (single) smallest lat_n greater than 38
FETCH
Same effect as OFFSET and LIMIT. Requires ORDER BY clause in order to to get consistent output. No commas just like LIMIT OFFSET.
ORDER BY foo, -- required
OFFSET m {ROW | ROWS}
FETCH [FIRST | NEXT] n {ROW | ROWS} ONLY;
UPDATE
UPDATE table_name
SET field1 = value1,
field2 = value2
[WHERE Clause]
DELETE FROM
DELETE FROM table_name
[WHERE Clause]
Aggregate & Scalar Functions
Aggregate Functions
They take as input, a collection of values and return a single scalar value.
- MIN(), MAX()
SELECT MIN(marks_maths) FROM RESULT-2020 WHERE BATCH='OP1'SELECT MIN(Price) AS SmallestPrice FROM Products; - COUNT(), AVG(), SUM()
Of all the aggregate methods, only COUNT() doesn’t ignore NULL values.
Scalar Functions
They also return a single scalar value based on some input that can be a collection of values.
LEN() LCASE() UCASE() MID() CONCAT() RAND() ROUND() NOW() FORMAT()
Arithmetic Operations
SELECT name, price * 0.25 from items;
SELECT name, ROUND(price - (price * 0.25), 2) from items; -- scale = 2, ROUND(expr, scale)
SELECT name, ROUND(price - (price * 0.25), 2) AS discounted_price from items; -- aliasing column
COALESCE(), NULLIF(), CAST()
-- COALESCE: returns first non-null value from the left among the arguments
SELECT COALESCE(null, null, 1, 10) from customers; -- 1
SELECT COALESCE(is_smoker, 'No') from customers;
-- NULLIF: returns NULL if both the arguments are equal otherwise left arg
NULLIF(9, 9)
NULLIF (1, 0); -- returns 1
NULLIF ('A', 'B'); -- returns A
-- CAST
CAST('2022-06-23' AS DATE)
CAST('78' AS INTEGER)
CAST('8.99' AS DOUBLE)
ALIAS
# Column Aliases
SELECT price AS cost FROM table;
SELECT price cost FROM table; -- ommitting AS
# Table Aliases
SELECT item, price FROM table AS t;
SELECT item, price FROM table t; -- ommitting AS
GROUP BY
Used in conjunction with aggregate functions. To group their results together based on a particular column.
SELECT COUNT(CustomerID), Country
FROM Customers
GROUP BY Country -- count() is grouped; otherwise it would not have been
(*we can skip Country from projection but that doesn’t make any sense)
HAVING
The WHERE clause places conditions on the selected table columns, whereas the HAVING clause places conditions on groups (query result columns) created by the GROUP BY clause or aggregate functions. We can’t have a HAVING clause without a GROUP BY clause.
SELECT COUNT(CustomerID), Country
FROM Customers
GROUP BY Country
HAVING Country = 'USA';
ORDER BY
Orders by any column(s). It sorts the result-set (WHERE clause’s output) and not the final projection, thus the columns in ORDER BY clause need not be present in the final projection attribute list.
select long_w from station
where lat_n < 137 order by lat_n desc limit 1;
-- gets the (single) maximum lat_n less than 137 and displays corresponding long_w
Subqueries
We can have simple and correlated subqueries. Use subqueries with EXISTS/NOT EXISTS, IN/NOT IN, ANY/ALL clauses.
-- subquery in projection
SELECT atribute1, attribute2, (subquery) FROM demo;
-- select from subquery; aka Derived Table
SELECT atribute1, ..., attributeN FROM (subquery) AS subquery_alias;
-- alias is mandatory as because everything in the FROM clause must have a name
Two types of subqueries:
-- simple subquery: inner query is independent of outer query
-- employees whose salary is greater than average of all employees in the company
SELECT
employee_id, first_name, last_name, salary
FROM
employees
WHERE
salary > (SELECT AVG(salary) FROM employees) -- executed only once for all rows of outer query
-- correlated subquery: inner query uses outer table's column
-- employees whose salary is greater than average of all employees in thier respective departments
SELECT
employee_id,
first_name,
last_name
FROM
employees e
WHERE
salary > (SELECT AVG(salary)
FROM employees
WHERE department_id = e.department_id); -- correlation; executed once for each row for all rows of outer query
EXISTS
The EXISTS operator returns true if the subquery returns one or more records, else false.
SELECT SupplierName
FROM Suppliers
WHERE EXISTS (SELECT ProductName FROM Products WHERE Products.SupplierID = Suppliers.supplierID AND Price < 20);
ANY, ALL
They are used to compare a single column to a set of columns from subquery output.
ANY: compares current column and any value in subquery output. SOME is an alias for this clause.
ALL: compares current column and all values in subquery output.
SELECT ProductName
FROM Products
WHERE ProductID = ANY (SELECT ProductID FROM OrderDetails WHERE Quantity = 10);
-- lists productIDs in Products table which are equal to any one ProductID in OrderDetails table
SELECT ProductName
FROM Products
WHERE ProductID < ALL (SELECT ProductID FROM OrderDetails WHERE Quantity = 10);
-- lists productIDs in Products table which are less than all ProductIDs in OrderDetails table
SELECT INTO
Insert attributes into new table from an existing one.
SELECT column1, column2, column3, ...
INTO newtable [IN externaldb]
FROM oldtable
WHERE condition;
SELECT *
INTO newtable
FROM oldtable
WHERE 1=2;
(* Copying shema only into an empty table)
INSERT INTO SELECT
Insert data from matching corresponding attributes from one table to another.
INSERT INTO table2 (column1, column2, column3, ...)
SELECT column1, column2, column3, ...
FROM table1
WHERE condition;
CASE
CASE
WHEN condition1 THEN result1 -- notice no comma separator
WHEN condition2 THEN result2
WHEN conditionN THEN resultN
ELSE default_result
END
-- another way
CASE(expr)
WHEN value_of_expr1 THEN result1
WHEN value_of_expr2 THEN result2
WHEN value_of_exprN THEN resultN
ELSE default_result
END
SELECT OrderID, Quantity,
CASE WHEN Quantity > 30 THEN 'The quantity is greater than 30'
WHEN Quantity = 30 THEN 'The quantity is 30'
ELSE 'The quantity is under 30'
END AS QuantityText
FROM OrderDetails;
CASE(animal_name)
WHEN 'Dolphin' THEN 'Mammal'
WHEN 'Shark' THEN 'Fish'
WHEN 'Snake' THEN 'Reptile'
ELSE 'Unspecified'
END
Set Operations: UNION, UNION ALL, INTERSECT, MINUS
SELECT column_name(s) FROM table1
UNION / UNION ALL
SELECT column_name(s) FROM table2;
(* UNION ALL keeps duplicate tuples whereas UNION does not)
- Each SELECT statement under UNION must have the same number of columns
- The columns must also have similar data types
- The columns in each SELECT statement must also be in the same order
SELECT City, Country FROM Customers
WHERE Country = 'Germany'
UNION
SELECT City, Country FROM Suppliers
WHERE Country = 'Germany'
ORDER BY City; --applies to whole union-ed table
MINUS: query1 MINUS query2 (All rows in query1 which are not in query2). Alias for this clause is EXCEPT in Postgres.
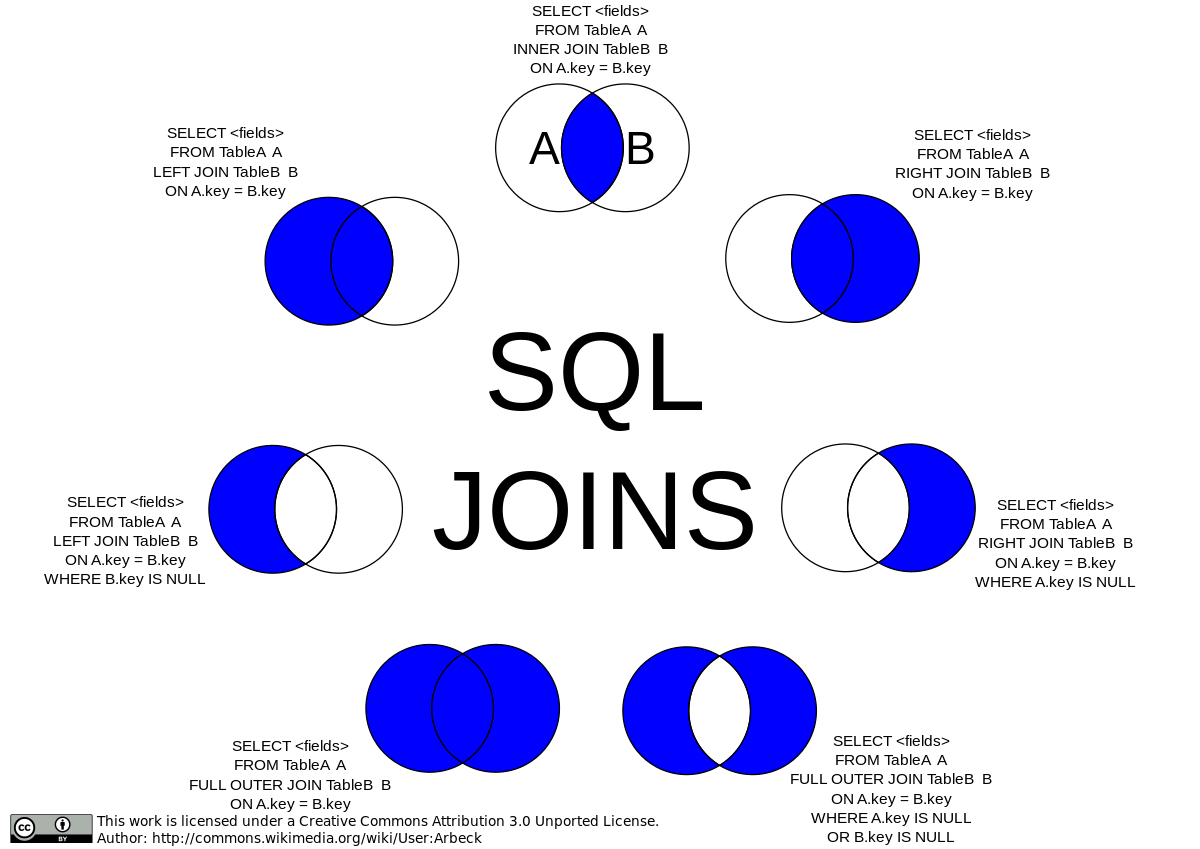
JOINS
JOINs are cross-product with filters applied on it.
EQUI JOIN: Any of the above joins that performs join based on equality = of two columns, each in either table. Ex - A.x = B.y
NATURAL JOIN: A type of EQUI JOIN where column names are exactly the same. Ex - A.x = B.x
SELF JOIN: Join that is performed on a single table on itself. Two columns from the same table are used to perform join.
A FOREIGN KEY is automatically created in a JOIN if a suitable candidate is not present.
INNER JOIN
When table A(1,2,3,4) and table B(3,4,5,6) are inner-joined, the output will be (3,4). We can join more than two tables too. We join based on some column(s) from each table to match data.
It is basically intersection set operation.
SELECT a
FROM A
INNER JOIN B ON b = a;
-- three tables
SELECT A.n
FROM A
INNER JOIN B ON B.n = A.n
INNER JOIN C ON C.n = A.n;
Outer Joins
LEFT JOIN
SELECT A.n
FROM A
LEFT JOIN B ON B.n = A.n;
Display full table on the left but places NULL on values not in Right table.
RIGHT JOIN
SELECT A.n
FROM A
RIGHT JOIN B ON B.n = A.n;
Display full table on the right but places NULL on values not in Left table.
FULL [OUTER] JOIN
SELECT A.n
FROM A
FULL [OUTER] JOIN B ON B.n = A.n;
Display entries from both the tables but places NULL on values not in each other.
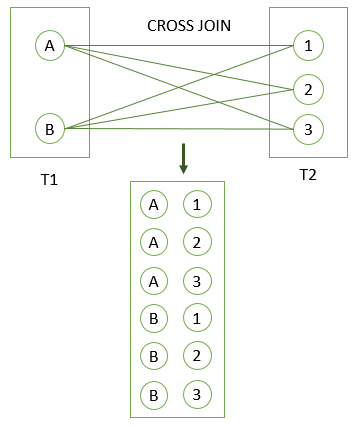
CROSS JOIN
It is cartesian product m x n rows of two tables so no predicate is required.
It is equivalent of doing INNER JOIN with condition as true since there is no predicate.
-- all of the below are equivalent
SELECT select_list
FROM T1
CROSS JOIN T2;
SELECT select_list
FROM T1, T2;
SELECT *
FROM T1
INNER JOIN T2 ON true;
Other Joins
SELECT select_list FROM T1
NATURAL [INNER, LEFT, RIGHT] JOIN T2;
SELECT * FROM city
NATURAL JOIN country;
SELECT * FROM products
INNER JOIN categories USING (category_id);
Joins Summary Chart
TCL
BEGIN; -- begin a transaction
COMMIT; -- cannot rollback to a point after a commit
SAVEPOINT savepoint_name;
ROLLBACK TO savepoint_name;
ROLLBACK; -- rolls back to latest savepoint; or latest commit
SQL Constraints
Around 9 constraints are listed below.
- PRIMARY KEY (Not Null + Unique)
CREATE TABLE demo(
id int NOT NULL PRIMARY KEY, --column level since single PK
name varchar(20)
);
CREATE TABLE demo(
id int,
name varchar(20),
PRIMARY KEY(id)
);
CREATE TABLE demo(
name varchar(20),
id int NOT NULL,
[CONSTRAINT key_alias] PRIMARY KEY(name, id) --table level since multiple PK, single also allowed
);
- FOREIGN KEY: (Uniquely identifies a row/record in another table i.e. it is Primary Key of some other table and doesn’t have to be unique in current table)
PersonID int FOREIGN KEY REFERENCES Persons(PersonID) -- column level
FOREIGN KEY (PersonID) REFERENCES Persons(PersonID) -- table level; same effect as above
CONSTRAINT FK_PersonOrder FOREIGN KEY (PersonID) REFERENCES Persons(PersonID) -- same but uses CONSTRAINT keyword; table level
- UNIQUE
- NOT NULL
- CHECK (Ensures that all values satisfy a specific condition)
CHECK(salary >= 3)
Age int CHECK(Age >= 18) -- column level; single column check
CONSTRAINT CHK_Person CHECK (Age >= 18 AND City = 'Seattle') -- table level; multiple column check
- DEFAULT (Sets a default value for a column when no value is specified)
DEFAULT "John Doe" - INDEX
- ENUM or SET (Only values in enum or set are allowed)
CREATE TABLE t_name (
col1 int NOT NULL UNIQUE,
col2 varchar(255) DEFAULT 3,
col3 varchar(255),
col4 int,
);
ALTER TABLE to apply Constraints later
ALTER TABLE demo
ADD PRIMARY KEY(id);
ALTER TABLE Persons
ADD CHECK (Age >= 18);
ALTER TABLE demo
DROP PRIMARY KEY;
Auto-increment, Sequences, Identity
id int AUTO_INCREMENT -- MySQL; column level
id int SERIAL -- Postgres; column level
-- we can also create a sequence and SERIAL uses sequence internally with step = 1, init val = 0
-- Identity colummn is also provided in Postgres which also uses sequences internally
Built-in Functions
left(str, n)andright(str, n): Substringing from left and right respectively.round(expr, scale): Rounding decimalabs(expr): Returns absolute valuepow(expr, exponent): Raise expression to exponent power
GROUPING SETS, ROLLUP, CUBE
We often group aggregate methods using GROUP BY and specify columns to group onto. All three are alternate syntax to avoid writing complex GROUP BY and manually perform UNION ALL on queries.
-- GROUP BY with UNION ALL
SELECT count(*) FROM employees GROUP BY first_name;
UNION ALL
SELECT count(*) FROM employees GROUP BY last_name;
UNION ALL
SELECT count(*) FROM employees;
-- equivalent query using GROUPING SETS; we can specify sets to group by inside parentheses
SELECT count(*) FROM employees
GROUP BY GROUPING SETS (
first_name,
last_name,
()
);
-- () means no gouping (it will return count(*) for the whole table)
-- another example with composite grouping sets; equivalent to ROLLUP
SELECT count(*) FROM employees
GROUP BY GROUPING SETS (
(first_name, last_name),
(first_name),
(last_name),
()
);
-- ROLLUP
SELECT count(*) FROM employees
GROUP BY ROLLUP ( first_name, last_name );
-- shows result of group by none, group by all 3, group by 2, group by just 1
-- CUBE
SELECT count(*) FROM employees
GROUP BY CUBE ( first_name, last_name );
-- shows result of group by for all combinations (2^n power set)
References: Working with Rollups and Cubes in SQL
CTE (Common Table Expression)
CTE allow us to create a temporary table and perform query on it. The table is destoryed as soon as the query is finished executing.
-- syntax
WITH cte_name [(column_list)] AS (
CTE_query
)
query;
-- example
WITH cte_film AS (
SELECT film_id, title
FROM film
WHERE release_year <= 2000
)
SELECT film_id, title
FROM cte_film -- notice
WHERE genre = 'Sci-Fi';
We could have acheived this with subqueries too.
Views
They are used to create a separate data stucture which we can query instead of directly querying on tables.
A view can have attributes from multiple tables, so instead of running a complex JOIN query, we can create a view and simply query that.
They differ from CTE or subqueries is that an actual physical object is created and stored whose scope is even beyond that of query.
CREATE VIEW view_name AS query;
-- query can be any JOIN query that outputs a projection having columns from multiple tables
-- when we query a View, we are effectively querying this complex JOIN query's output
We can also UPDATE and DROP views too just like regular tables.